Rotary Machine Monitoring
4 min read
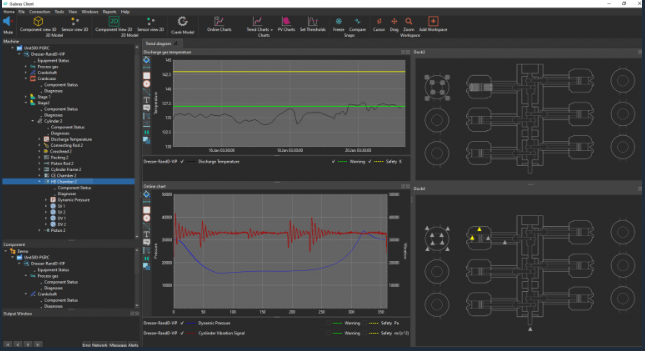
Introduction
This software monitors rotary equipment, including reciprocating compressors and turbines, at industrial sites. It collects data from hardware sensors and shows critical readings in real time. Our product called Gubras is now installed in Parsian and Isfahan refineries and Shariati power plant. We compared it to leading industrial monitoring tools and found that it offers more features in certain areas, such as scheduling data captures around maintenance events.
Key Features and Data Flow
The hardware gathers readings for proximity, vibration, and pressure. It sends this information to our software using UDP, which updates live displays and stores selected records in a database for later review. Users can define thresholds for important metrics, and the software raises alerts when readings go out of range. The system also has 2D and 3D diagrams, along with a tree structure that lets you organize parts of a single device or an entire plant.
One of the most useful features is the ability to keep track of sensor data before and after maintenance work. Operators can compare these points to figure out why a machine failed or performed poorly. This approach has helped them plan repairs and avoid future downtime.
Project Scale and Process
Our backlog included over 1000 user stories and more than 100 epics. We followed an agile process, which meant frequent sprints, daily stand-ups, and regular retrospectives. This structure helped our team handle the growing list of requests and improvements. I also led weekly leadership meetings to discuss technical decisions and plan development milestones.
My Role
I served as a Senior Software Engineer, shaping the software architecture with our manager and assigning tasks to junior developers. I worked on math-heavy parts of the backend by using the Armadillo C++ library, which helped manage the performance challenges when processing sensor data. I also wrote a Python wrapper for neural network algorithms, so we could run predictive models inside our main application.
Another important task was migrating our database from Cassandra to PostgreSQL. This change boosted query performance by about 2.5 times, which made the system faster for operations that read or analyze large volumes of data.
Tech Stack
- Languages & Frameworks: Qt/C++, Python
- Database: PostgreSQL
- Version Control & CI/CD: Git, Jenkins
- Project Management: Jira, Confluence, Agile methods